Michael Nasello
Data Scientist, Machine Learning Practitioner
About Me
I am a passionate learner who enjoys developing new skills and leveraging them to solve challenging
problems. To me, nothing is more exciting than struggling through a problem and finding that
breakthrough solution. While studying Mechatronics Engineering at the University of Waterloo, I
have been presented with countless opportunities to do so. Collaborations with classmates has
introduced me to several interesting areas, including Machine Learning.
Outside of the classroom, I use my time to develop as a Machine Learning practitioner. By
watching video lectures, reading books/articles, and completing several side-projects, I have
grown a valuable knowledge base in the area. During internships, I employ my skill set to tackle
complex and interesting problems.
In my free time I enjoy weight lifting, running, golf, and soccer.
Work Experience
Data Scientist
May 2022 - August 2022 Toronto, ON
Employer Evaluation: OUTSTANDINGDuring my time at Intact’s Data Lab on the Speech Analytics Claims team, I worked on the first implementation of a Reason-of-Call model. This system, at scale, ingests recordings of conversations between customers and our Adjustors, transcribes the dialogue to text, and maps the text to one of many Reason-of-Call labels characterizing the primary purpose of the call.
By understanding the purpose of calls along with other key statistics and trends at our call-centers, we can identify and remove pain points to reduce the time our Adjustors spend on the phone. Our business team projects this will lead to an estimated 2 million dollars in reduced operational expenses over the next three years.
My specific contributions range from data and modelling experiments to the implementation of Data Science best-practices to the ideation of business use-cases. I developed Active Learning strategies to make more efficient use of the limited access to annotators, tested several architectures of our RoBERTa model’s classification head, added K-fold Cross Validation to training scripts, performed hyper-parameter tuning, built a GUI that connects to MLflow for rapid model error analysis, etc.
In addition to the above work, one notable effort I led was the application of text augmentation to our data during oversampling. Text augmentation will change wording without obstructing the proper flow of speech nor changing the underlying message. This is done via back translation, where text is translated to another language and back, and random replacement, where words are masked and replaced by a mask-fill model at random. This work is now used by other teams in the Data Lab.
Data Scientist
January 2022 - April 2022 Toronto, ON
Employer Evaluation: OUTSTANDINGDuring my time at Omnia, Deloitte’s AI practice, I developed both technical and consulting skills while working across sectors, clients, and types of work. Outside of technical work, I contributed to Work Proposals, Statement-of-Works, and client-facing presentations.
A notable project I joined served one of Deloitte’s large public sector clients. This client maintains a public-facing inbox, with daily volumes sometimes reaching 1000 emails. My team recommended they leverage AI to relieve the stress of doing so manually. I built a proof-of-concept to illustrate how we could, at scale, identify high-quality sources of information to answer questions.
My approach was two-fold. Provided a question, perform a search of all ~5000 pages belonging to the client’s website. A question-answer language model projects both the user query and all text, scraped and cleaned, into a dense vector space for semantic search. All pages are ranked based on cosine similarity and strong matches to the question are returned. With this approach, the user is directed to potential answers before hitting send, and the client is saved a correspondence.
When the above approach fails, and the unanswered question arrives at the inbox, a search of all past correspondences is executed. Our hypothesis is: for past questions that are semantically similar, their responses contain valuable information and provide a templated response. We leverage a question-answer language model to generate embeddings of the query and all past emails. Since the search space is large, we filter the field of candidates via a k-means clustering algorithm. It then becomes feasible to rank the remaining candidates, via cosine similarity, and present the results.
This system has the ability to greatly lessen the burden of maintaining the client’s inbox by reducing the number of correspondences received, automatically identifying relevant information, and drafting template responses.
Applied Machine Learning Intern
May 2021 - August 2021 Toronto, ON (Remote)
Employer Evaluation: EXCELLENTDuring my time at the Vector Institute, I worked on the AI Engineering and Technology team. The majority of my time was dedicated to Project Pensive, a new initiative aiming to combat some of social media's biggest problems.
On social media platforms, Recommender Systems are responsible for generating feeds based on user preferences. Unfortunately, at times, current implementations can suggest content that is uncivil, polarizing, and disengaging. Project Pensive builds a tool leveraging Machine Learning and Natural Language Processing to generate more thoughtful (pensive) recommendations.
I leveraged PyTorch to build a Recommender Engine that suggests comments on the popular Reddit platform. These suggestions are based on the preferences of users in a Reddit dataset. With the Hugging Face library, I built and trained a BERT-based civility classifier that can process and assign toxicity scores to text.
This work was combined with my teammate's diversity algorithms to build an elaborate demonstration simulating the experience of a user navigating Reddit with our tool. Suggested content is more civil, less polarizing, and less disengaging.
This work is open-sourced. Links are available to view the code and tool in action.
Deep Learning Developer
September 2020 - December 2020 Waterloo, ON (Remote)
Employer Evaluation: EXCELLENTDuring my time at Applied Brain Research (ABR), I worked on NengoCloud: a cloud service for training power-conscious Keyword Spotters with targeting for various hardware backends.
Language models such as BERT or GPT-2 are powerful, but expensive in terms of power consumption and memory. They are not feasible for always-on devices. Instead, we design much more lightweight Keyword Spotter models that can recognize wake-words, and then activate those bigger language models when appropriate.
My contributions to NengoCloud began with market research, compiling a list of hardware candidates used by popular Edge-AI devices. I surveyed popular cloud-training services for Edge-AI and extracted a list of common user-facing options.
My coding time was dedicated to building Keyword Spotters for the Coral TPU. A feed-forward implementation of the RNN was necessary for compatibility with the TPU compiler. I authored code that provides the functionality to compile these models and run on-device testing from a server. I built a comprehensive Command Line Interface, that can run the full NengoCloud pipeline.
To provide a proof-of-concept of the product, I trained models on Google’s Speech Commands v2 dataset. Notable results include ~97% training validation accuracy and, after model quantization and compilation, ~95% on-device testing accuracy.
Machine Learning Developer, Data Scientist
January 2020 - April 2020 Ottawa, ON
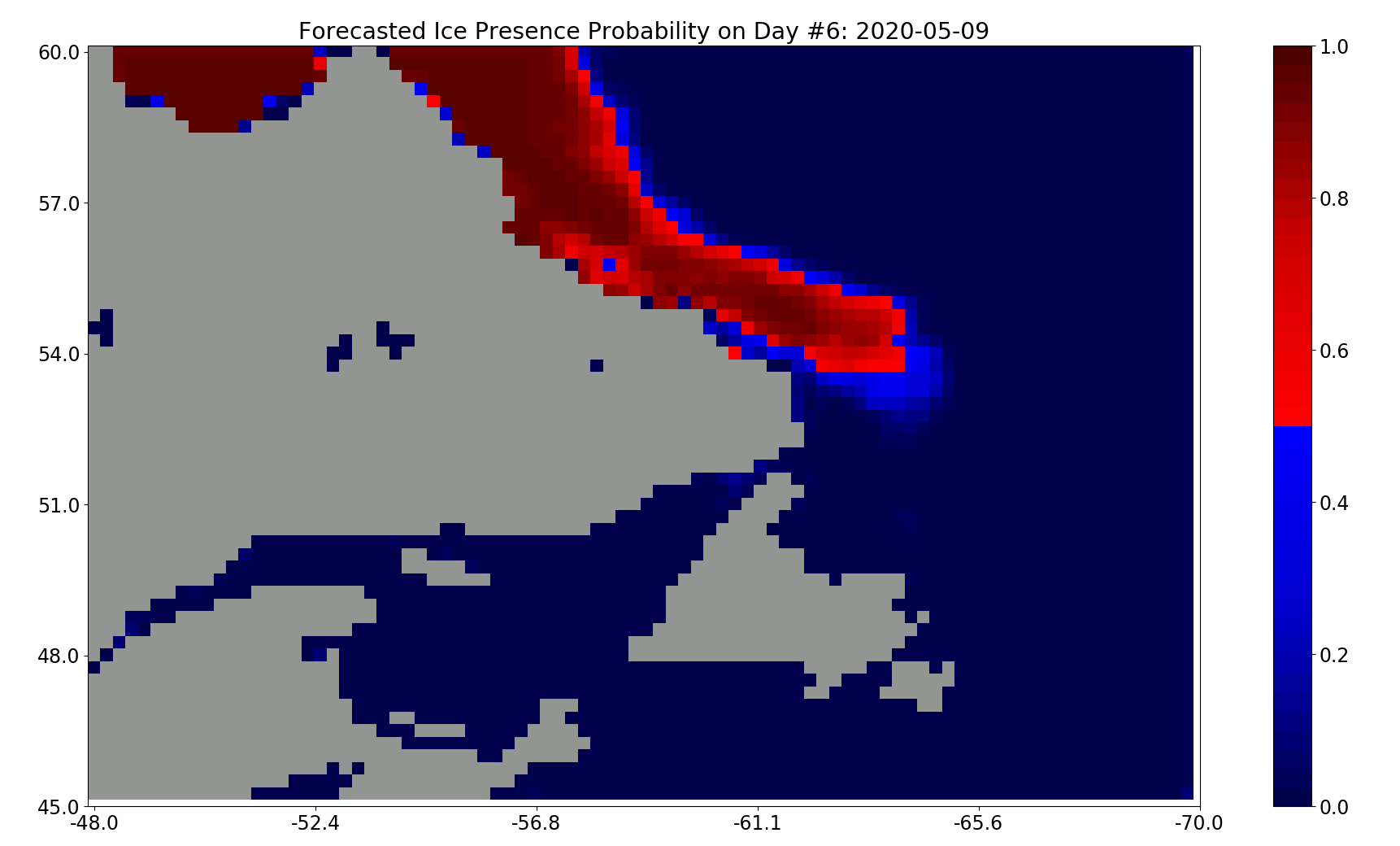
Employer Evaluation: EXCELLENTDuring my time at the National Research Council (NRC), I worked on a project where we developed Machine Learning models to forecast sea ice presence in several large Canadian bodies of water. Over freezing and melting seasons, it is difficult to predict the safety of trade routes across Canada. To increase the confidence window, we leverage these models.
These forecasting models incorporate ConvLSTMs and a custom SIF-Net RNN architecture. They take rasters of environmental variables (e.g. precipitation, temperature, windspeed) and generate 30, 60, and 90-day predictions.
My contributions included adding to the existing model training pipeline and deploying final products to AWS. I conducted rigorous experimentation with model inputs and hyper-parameters to maximize performance. I wrote code for the deployment of the project to AWS; using Fargate, ice presence forecasts are generated each day and available for view on a static webpage I developed (see link below).
I wrote a work term report summarizing my contributions, available via the link below.
Machine Vision Support Engineer
April 2019 - August 2019 Windsor, ON
Employer Evaluation: EXCELLENTAs a Machine Vision Support Engineer at Vista, I was responsible for developing Machine Learning solutions for projects where traditional methods of Machine Vision could not perform at a level required by the client. I worked on several projects during my co-op. I spent a majority of my time carrying an Object Detection project to completion.
I was also responsible for training Vista Engineers and providing an introduction to Neural Networks. I delivered a webinar presentation that introduced the general structure of Neural Networks, the mathematics behind model training, and how these concepts can be implemented into their custom applications.
I on-boarded Vista Employees with my work, prior to my departure, and trained the incoming co-op student. I was requested for continual support related to Vista's Machine Learning projects.
Projects

Neural Networks from Scratch
The goal is to build a Python package providing the necessary functionality for
training Neural Network models from scratch. No TensorFlow or PyTorch. Just
old-fashioned Python and its computing library, NumPy.
To demonstrate a fundamental understanding of Neural Networks and their complex
intricacies, I built custom implementations for many common techniques and
structures. Written is code for trainable parameters, model layers, optimizers,
loss functions, and other needed infrastructure. Using this package, one can
build Neural Networks and achieve convergence on a variety of Machine Learning
problems.
More work will be done to improve convergence during training and to support
other layers, optimizers, loss functions, etc.

Autonomous Mini Cart
The goal of this project is to build a Mini Cart, powered by a
Raspberry Pi,
that can take directions without direct human intervention. A camera is mounted
to the front of the cart chassis. Pictures are taken and processed through a
Machine Learning algorithm to extract instructions.
Instructions include: 'go left', 'go right', 'go forwards', 'stay'. After a proof
of concept is acquired, speed controls will be added. The user simply has to
point in the direction of travel and the Mini Cart responds appropriately.
More information on this project will be posted in the
Featured Work section of this page. To view the
source code, a GitHub link is provided.
Deployment of Sifnet ML Model
When working at the NRC, I was asked to develop a method by which end users could
access final products. Ice presence forecasts needed to be generated daily
and available for download. I pioneered and finished the complete deployment
pipeline of the project.
Using docker, I containerized the application and pushed
the image to AWS. I then leveraged the flexibility of
AWS Fargate;
scheduled tasks run daily and products are automatically uploaded to AWS s3. A
website was created to display products and validation graphs of our models.
Below you can access the website I created to view and download final products.
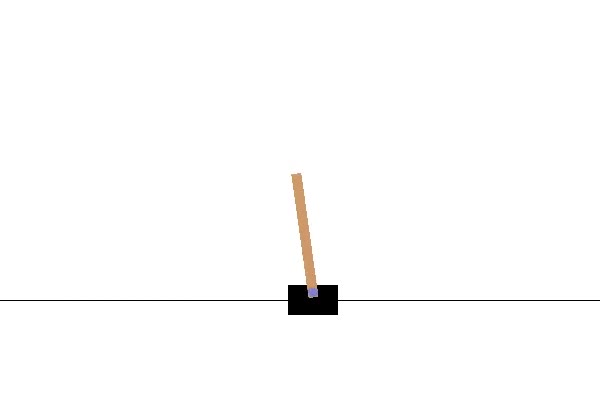
Reinforcement Learning with CartPole
The goal of this project is to stand the pole upright for as long as possible; a
traditional controls problem, but with the twist of using a Reinforcement Learning
approach. Through the use of OpenAI Gym's environment, I am given control of the cart.
The cart can move either left or right. My task is to determine, given a 4D vector
[Position, Velocity, Angle, Angular Velocity], the action that will maximize the
probability that the pole does not fall over, both in short and long term.
Below you can access my Github Repo and the documentation for OpenAI Gym.


Mechatronics Cornerstone Project
This was a first-year, first-term design project for all Mechatronics Engineering
students at the University of Waterloo. It was an open-ended project. We were given
a lego set and an EV3 controller. Monitoring and defending personal space was the task
we chose.
The final product surveyed an area and fired projectiles at approaching
objects. Chassis composed of lego; source code written in RobotC. During the closing
phase of the project, a final report was produced that summarized project scope,
constraints and criteria, mechanical and software design and methods of testing.
Featured Work
Autonomous Mini Cart
The Mini Cart is designed to follow directions without pre-programmed instructions. The end user can simply point in the desired direction of travel and the robot will react accordingly. Computer Vision and Machine Learning are used to determine intended commands from instructor.Raspberry Pi
The Mini Cart is powered by a Raspberry Pi; the Pi is responsible for all ML computations, capturing pictures via the Pi camera, and reacting by powering servo motors with GPIO (General Purpose Input Output) pins. A Python virtualenv was used to install and manage essential Python packages, including Tensorflow, Numpy, Pillow, RPi.GPIO and Picamera.

Chassis
The Mini Cart chassis holds the Pi, Pi-Camera, servo motors, wheels, two power banks, and a breadboard circuit supporting drive functionality. A custom camera mount was built and installed on the front of the mini cart.


Machine Learning
A simple CNN was implemented to generate predictions. One issue specific to this project was model size. It was impossible to load the original model (~400MB) into memory on the Raspberry Pi; this is a common problem for ML 'at the edge'. Several steps were taken to reduce the model size to ~2MB. The model was quantized to use float16 precision (from float32). The model was further compressed using Tensorflow Lite.
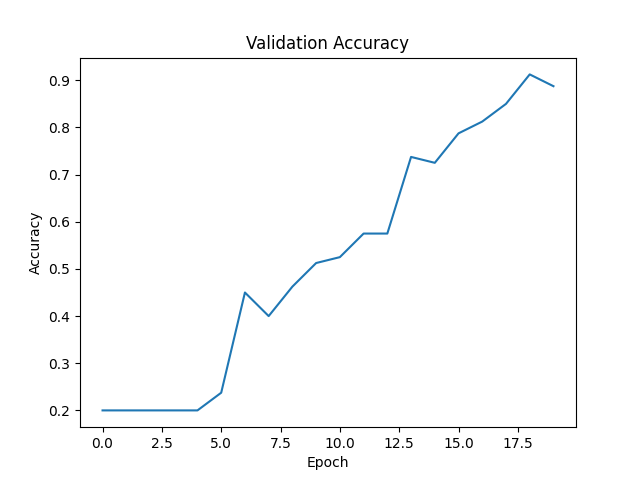
In addition, images from the dataset were resized to 256 by 256 images (from 512 by 512). This decreased the size of convolution layer outputs and number of parameters in dense layers later in the network. I created my own dataset, gathering approximately 400 images of myself pointing in various directions. There was a 80 / 20 percent split of training and validation images, respectively. On the validation set of 80 images, an eventual accuracy of 88% was achieved.
Below you can observe the progress of training.
Final Product
Problem
The goal of this project was to develop a policy the CartPole can follow so that it stands upright. At each time step, OpenAI Gym provides the cart's position, angle, velocity, and angular velocity. It is our job to use this information to determine what action should be taken that will maximize the probability that the CartPole remains standing upright. Possible actions are moving left or right.Approach
Reinforcement Learning was used to solve this problem. This concept is synonymous to positive/negative reinforcements in real life:
If a dog behaves, they receive a treat; if they misbehave, you put them in their cage. After time, the dog figures out what is considered good/bad behaviour based off of the consequences.
This approach can be used to our advantage when training AI. The reinforcement learning application consists of four entities:
- The environment (OpenAI Gym / Your house)
- The agent (CartPole / The dog)
- The action space (Move left or right / Behave or misbehave)
- The reward (Number / Give treat or put in cage)
The approach for solving this problem is the following: train the CartPole to take actions that maximize its reward.
How is the network trained?
For a given state, it is the network's job to output a vector of probabilities for taking each action in the action space. When training, we attempt to minimize the difference between that output and the action that maximizes rewards.
For example, if the CartPole is currently travelling to the left, it is preferable to reverse that movement and begin travelling to the right. Thus, a desired output from the model is [0, 1] ([Going left, Going right]). A network without training won't necessarily generate that output. The optimizer's job is to adjust the network so that the vector approaches [0, 1] when the CartPole is moving left.
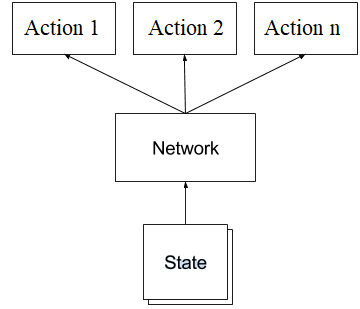
So our loss function attempts to minimize that difference. How are rewards used?
We multiply our gradients by the rewards. When performing Back Propagation, positive rewards (agent did something right) will cause the optimizer to descend down the gradient. The opposite is true for negative rewards (agent did something wrong). This process has the effect of 'learning' what the appropriate actions to take are, given a state from the environment.
The Credit Assignment Problem
There is a fundamental problem with how rewards are calculated: how does the agent know if falling at t = 100 was caused by an action at t = 98 or t = 17? This is known as the 'Credit Assignment Problem'.
To solve this problem, we apply a discount rate to our rewards. For each time step:
Discounted Reward [t = t] = Reward [t = t] * pow(discount_rate, 0) + ... + Reward [t = t + n] * pow(discount_rate, n)
Note: discount_rate belongs to (0, 1)
What does this accomplish? This decreases the impact that a future reward has on the current time step. Using discounted rewards, the agent, over many games, is able to 'learn' what actions, given a corresponding input from the environment, are beneficial.
Model
The tf.keras API was leveraged for the formulation of models. Each model architecture developed consisted of a series of fully-connected layers. Dropout was used for the final design; this design performed the best during testing.
The final design, model_v5, consisted of the following:
Dense(32) → Dropout → Dense(32) → Dropout → Dense(32) → Dropout → Dense(32) → Dropout → Dense(32) → Dense(2) → SoftmaxResults
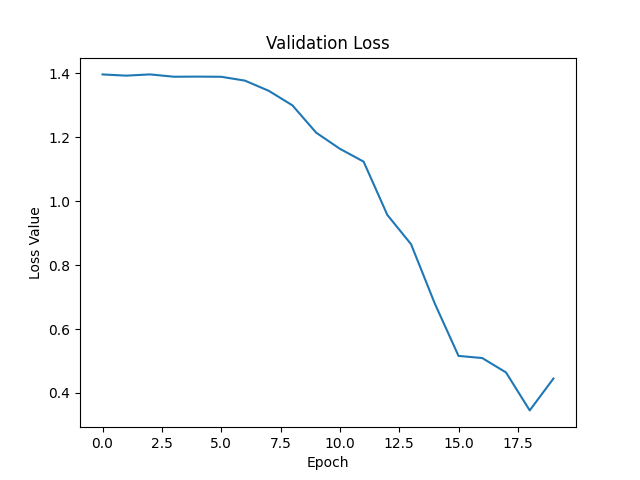
After 5 iterations of the model architecture, a policy model was trained that converged and was able to survive in the environment. The program was manually stopped at 15,000 steps (about 5 minutes). It took 900 episodes of training to reach this point. Below is a video showing the agent's progress throughout the training loop.
Acknowledgements
Three resources were used to help me as I learned about Reinforcement Learning:
- I was introduced to the idea while completing Jose Portilla's Complete Guide to TensorFlow for Deep Learning with Python course on Udemy.
- Much of the implementation for this project was inspired by this Medium post.
- This Medium post provided much of the necessary background and basis for this project.
Problem
The goal is to correctly classify a single handwritten digit given an arbitrary image. To test out the performance of my model, click on the link below.Approach
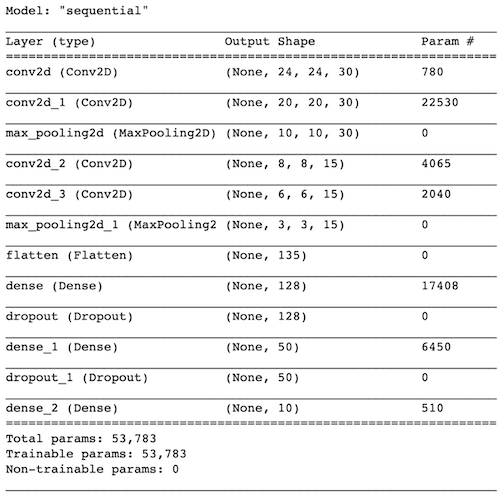
Machine Learning was used to solve this problem. Using the tf.keras API, a Convolutional
Neural Network was trained on the MNIST dataset. The following model architecture was
used.
Thanks to Google, I was able to train on a state-of-the-art TPU (Tensor Processing Unit)
through their free cloud service: Google Colab. On the MNIST dataset, I reached a
validation accuracy of approximately 99.2%.
It is important to note that the
numbers of the MNIST dataset are written in pen, while we are using an HTML
canvas to draw our numbers; this could slightly impact model performance.